Learning to assign Local Reference Frame for 3D Point Cloud
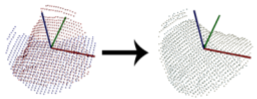
The idea of this research is to assign a local reference frame to the target point cloud before doing feature description, so as to get a descriptor which is invariance to rotations. The concept has been widely applied in some famous conventional 3D feature descriptors, e.g. SHOT[2], PS[3], USC[4], EM[5] and MeshHog[6]. As well as learning based method, e.g. CGF[7]. As well as in 2D features SIFT[1].
There are many LRF methods has been proposed which work well on the 3D complete model. However, when it comes to the partial scan, point dropout or occlusion, the currently existing methods cannot perform well. That brings the idea of using deep learning to learn the local reference frame in the above mentioned difficult conditions.
Network Structure

We use Siamese loss to train our network with a self-designed equation to provide ground truth. The ground truth angle is defined as the shortest angle to rotate two point clouds to align. Instead of giving ground truth pose, we use the ground truth angle. We expect that the input point clouds which have a similar geometric shape should be grouped together in the embedded space.
Evaluation
We use the meters in [10] to evaluate our proposed method. We generate the evaluation model using the model from two public datasets: Standford[8] and UWA[9], with random downsample sample the point cloud and occlusions. The evaluation was down with two baselines: SHOT[2] and Flare[10].


Reference
[1] Ng, Pauline C., and Steven Henikoff. “SIFT: Predicting amino acid changes that affect protein function.” Nucleic acids research 31.13 (2003): 3812-3814.
[2] F.Tombari,S.Salti,andL.D.Stefano.Uniquesignaturesof histograms for local surface description. In ECCV, volume 6313, pages 356–369, 2010.
[3] C. S. Chua and R. Jarvis. Point signatures: A new represen- tation for 3d object recognition. IJCV, 25(1):63–85, 1997.
[4] F. Tombari, S. Salti, and L. D. Stefano. Unique shape context for 3d data description. In 3DOR, pages 57–62, 2010.
[5] J. Novatnack and K. Nishino. Scale-dependent/invariant lo- cal 3d shape descriptors for fully automatic registration of multiple sets of range images. In ECCV, 2008.
[6] A.Zaharescu,E.Boyer,K.Varanasi,andR.Horaud.Surface feature detection and description with applications to mesh matching. In CVPR, pages 373–380, 2009.
[7] Khoury, Marc, Qian-Yi Zhou, and Vladlen Koltun. “Learning compact geometric features.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
[8] B. Curless and M. Levoy. A volumetric method for building complex models from range images. In SIGGRAPH, pages 303–312, 1996.
[9] Mian, Ajmal S., Mohammed Bennamoun, and Robyn A. Owens. “A novel representation and feature matching algorithm for automatic pairwise registration of range images.” International Journal of Computer Vision 66.1 (2006): 19-40.
[10] Petrelli, Alioscia, and Luigi Di Stefano. “On the repeatability of the local reference frame for partial shape matching.” 2011 International Conference on Computer Vision. IEEE, 2011.